
Пошаговое руководство по проблемам развертывания моделей машинного обучения

За последние четыре года (в Google, и до этого в Comet Labs) мне довелось работать с сотнями стартапов и компаний по всему миру для того, чтобы помочь им определиться с их стратегией машинного обучения (МО), начиная от постановки задач до полного внедрения модели машинного обучения (МО), функционирующей в промышленной среде. Мы работали вместе над развертыванием модели для повышения эффективности работы (к примеру, внутренняя оснастка, DevOps — интеграция разработки и эксплуатации, и т.д.), избавлением от узкого места (к примеру, присваивая группе по обслуживанию клиентов «волшебные силы»), разрабатывали функциональные возможности машинного обучения (МО), и создавали новые проекты вместе.
В процессе работы мы подошли к развертыванию машинного обучения (МО) со всех сторон: технологическая реализация, разработка продукта, организационной структуры и культуры, управление персоналом, выход на рынок/установление цен/монетизация/ UI/UX и т.д. Во всяком случае, мы всегда начинали с сосредоточения на постановке задач, которые стремились решить благодаря модели машинного обучения. Этот статья сосредоточена главным образом на лучших практиках для определения вашей модели машинного обучения как успешной, масштабной, достоверной.
Перед тем, как вы прочтете эту статью, и проведете обсуждение проекта, у Вас должен быть четкий дальнейший план действий для направления первоначальной реализации вашего машинного обучения.
Шаг 0. Проведите предварительную проверку работоспособности.
Вне зависимости от этапа вашей компании, Вам следует сначала выполнить критический разбор текущей рабочей практики, узких мест, возможностей для роста, и предполагаемое развитие новых функциональных возможностей и продуктов. Существует множество способов максимально использовать машинное обучение как часть решения. Помните, что весьма вероятно, многие составляющие вашего бизнеса будут «общаться друг с другом» и воздействовать друг на друга после развертывания инфраструктуры анализа данных.
Сделайте свой бизнес более эффективным (более дешевым в эксплуатации).
Задайте себе следующие вопросы: Какие процессы являются основными для вашего бизнеса? Могут ли какие-либо из них (в будущем) оптимизированы? Просмотрите процессы, маркетинг, разработку продукта и т.д. Сколько времени/денег вы могли бы сэкономить от оптимизации одного трудового процесса другим? Сколько времени, вы думаете, займет, чтобы запустить автоматический рабочий процесс? Как вы планируете сохранить людей, нуждающихся в обучении? Где в вашем процессе потребуются люди?
Не забывайте, что этот процесс вероятнее всего будет болезненным, но это позволит Вам все в большей мере принимать решения на основе фактических данных, и сплотить людей в поддержку данных, а не произвольного процесса принятия решения.
Выбор одного рабочего процесса для оптимизации его машинным обучением, совместно с созданием мощной инфраструктуры анализа данных, позволит Вам последовательно оптимизировать все больше процессов и, возможно, даже приведет к разработке функциональных возможностей продукта.
Один из стартапов, с которым мы недавно сотрудничали, осознал, что одна из программ по обучению сотрудников стоила им 15 миллионов долларов в год. Они пытались выяснить, как автоматизировать раздел оценивания для процесса обучения с целью освобождения времени, которое люди тратят на оценку, чтобы удвоить усилия на обучении потенциально успешных сотрудников. Реализация их процесса, основанного на машинном обучении, позволило им снизить цену примерно на 30% после первого внедрения, а также начать обучение НПЛ-модели, которая с тех пор была включена в их продукт, в интересах повышения качества оказываемых ими услуг клиентам.
Дайте вашей команде и пользователям суперспособности.
Задайте себе следующие вопросы: Существуют ли внутренние инструменты, которые вы могли бы разработать, чтобы сделать ваших сотрудников, пользователей, и/или других лиц в вашей цепочке ценностей более эффективными?
Можете ли вы освободить время ваших сотрудников на должном уровне (в требуемом масштабе), например, настраивая, путем добавления элементов, аналогичных использованным средствам взаимодействия, или стандартизации процессов и типовых форм для стандартизации предоставления услуг. Можете ли вы в максимальной степени использовать опыт ваших сотрудников и других заинтересованных лиц в «маркировке» вашего набора данных, который, в конечном счете, приведет к лучшей предлагаемой продукции в целом.
К примеру, другой стартап, с которым мы сотрудничали, разработали «направляющую» функциональную возможность для их продукта, который генерировал тепловую карту вокруг аномалий на медицинских изображениях (снимках), на которые доктора должны обратить особое внимание. Это позволило докторам проводить примерно на 50% меньше времени, которое они тратили на сканировании изображений для аномалий, находящихся на высоком уровне, и сфокусироваться на статистически существенных частях на изображениях. Доктора потом добавляли ярлыки и примечания на эти изображения, которые затем возвращались в модель в качестве функциональной возможности. Их модель, полученная по результатам обработки, постоянно становится все более точной.
Отметим, что они не начинали, говоря, что «Модель машинного обучения должна иметь 99% точности», вы начинаете, говоря, что «продукт в совокупности должен иметь 98% точности», и чтобы добиться этого, мы можем использовать модель машинного обучения, которая имеет 99% точности на 90% входных параметров, но не принимает решения в 10%, и пропускает их группе специалистов, состоящих из трех экспертов — радиологов.
Вывести функциональную возможность или продукт машинного обучения на рынок
Задайте себе следующие вопросы: Какой набор данных вы собираете через существующий продукт/сервис? Сведения о действиях пользователя, обслуживании клиентов, и прочие? Как бы вы могли максимально использовать эти данные для разработки лучшего и более индивидуального предложения? Не могли бы вы в действительности построить совершенно новый продукт, целиком основанный на этих данных? Что если вы примите во внимание пример использования основополагающих принципов, сможете ли вы разработать совершенно новый продукт, основанный на сочетании существующих и новых источников данных?
Например, одна команда, с которой мы работали, совершенно изменили свою точку зрения на то, как обеспечить нейропластичность (т.е. способность мозга перестраивать себя, формируя новые нейронные связи), путем сбора совершенно нового набора данных через устройство захвата ЭЭГ, и сравнения различных результатов ЭЭГ для создания основанных на больших данных ЭЭГ «терапии». Люди начинают снова двигать своими конечностями – сумасшедшие! Следует отметить, что стоит быть крайне внимательным в том, как вы собираетесь формировать новые наборы данных и как вы оцените относительную ценность существующих наборов данных, которые вы извлекаете из своей модели – мы вкратце обратим внимание на предвзятости и объективности машинного обучения позже в этой статье.
В любом случае, важно определять отличие между проблемой и решением, а также между показателями продукта и показателями модели. «Машинное обучение» всегда является частью решения. Первый этап может быть таким «Мы хотим достоверно идентифицировать X». Вторым этапом является «Мы решаем использовать машинно-обучаемую модель как часть нашего процесса». Затем выделяют результаты, успешные метрики и цели для продукта в целом, которые всегда должны питаться от модели.
Шаг 1: Опишите свою проблему простым и понятным языком
Напишите, что бы вы хотели, чтобы машинно-обученная модель делала. На самом деле запишите: «Мы хотим, чтобы модель машинного обучения ____». Примером этого может быть: «Мы хотим, чтобы модель машинного обучения предсказывала, насколько популярным будет в будущем определенное видео, которое только загрузили». На данном этапе показатели могут быть качественными, но убедитесь, что они отражают вашу реальную цель, а не косвенную.
Шаг 2: Определите ваш идеальный исход
Ваша модель машинного обучения ориентирована на достижение желаемого результата. Что это за результат, независимо от самой модели? Заметьте, что результат может быть совершенно другим в зависимости от того, как вы оцениваете модель и ее качество (мы коснемся метрик в следующем разделе). Запишите: «Наш идеальный результат это: ____». Придерживаясь вышеприведенного примера, ваш идеальный результат может заключаться в том, чтобы только перекодировать популярные видео для минимизации использования обслуживаемых ресурсов, и предлагать видео, которые люди находят полезными, занимательными и стоят потраченного времени.
На этом этапе Вам не нужно ограничивать себя метриками, для которых ваш продукт уже оптимизирован (они будут рассмотрены на следующем шаге). Вместо этого попытайтесь сосредоточиться на более крупной цели вашего продукта или услуги.
Шаг 3: Определите ваши успешные метрики
Запишите ваши успешные и неудачные метрики, связанные с системой машинного обучения. Неудачные метрики важны (то есть, как вы узнаете, вышла ли из строя система машинного обучения?). Имейте в виду, что успешные и неудачные метрики должны быть сформулированы независимо от оценочных метрик для модели (к примеру, не говорите о точности, отзыве=чувствительности или AUC (Area Under the Curve) — область под кривой; вместо этого говорите об предполагаемых результатах). Зачастую эти метрики будут привязаны к идеальному результату, который вы установили выше. Напишите ответы на утверждения: «Наши успешные метрики это: ____», «Наши ключевые результаты (КР) для успешных метрик это: ____» и «Наша модель машинного обучения считается неудачной, если: ____».
К примеру, вашей метрикой успеха может быть использование ресурсов центрального процессора. В этом случае ваш ключевой результат для успешных метрик должен обеспечить снижение затрат на перекодирование центрального процессора на 35%, а модель машинного обучения будет считаться неудачной, если снижение стоимости ресурсов центрального процессора будут меньше затрат центрального процессора на обучение и обслуживание модели. Другими успешными метриками может быть количество правильно предсказанных популярных видео. Здесь ваш ключевой результат для успешных метрик должен верно прогнозировать лучшие 95% через 28 дней после загрузки видео. Ваша модель машинного обучения будет считаться неудачной, если правильно спрогнозированное количество популярных видео будет не лучше текущей эвристики.
Остановитесь здесь! Спросите себя: «Измеримы ли метрики?» «Как я буду их измерять?». Ничего страшного, если это будет живой эксперимент. Многие успешные метрики не могут быть собраны в автономном режиме. При выборе ваших метрик, подумайте об идеальном результате, который вы указали на предыдущем шаге. Когда вы можете измерить их? Сколько времени Вам понадобится, чтобы узнать, является ли ваша новая система машинного обучения успешной или неудачной?
Не ограничивайте себя бинарным противопоставлением успеха или неудачи. Есть более широкий диапазон: катастрофический / хуже, чем было / примерно такой же, как раньше / улучшение, но не так хорошо, как ожидалось / все замечательно. Также имейте в виду, что при наличии нескольких метрик система может находиться на одном уровне по одной метрике, а другая — по другой метрике.
Обязательно учитывайте расходы на проектирование и техническое обслуживание в долгосрочной перспективе прибыли. Отказ может произойти, несмотря на наличие успешных метрик. Например, модель может быть способна предсказать, будут ли они кликать на рекомендуемые видео, но она всегда может рекомендовать видео «наиболее кликающие».
Примечание по проверке проекта: вы заметите, что это руководство перемежается с «проверкой дизайна» для проверки вашего подхода перед переходом к следующему разделу. Мы настоятельно рекомендуем найти другую техническую службу или группу разработчиков (в вашей компании или за ее пределами), которая также в самом разгаре занимается развертыванием машинного обучения. Развертывание машинного обучения само по себе никогда не станет вашим секретным соусом (все дело в данных!), и вы действительно получите много пользы от обмена передовым опытом с другими практикующими специалистами, которые также находятся «в окопах». Если у Вас есть доступ к команде разработчиков облачных сервисов через вашего поставщика облачных услуг или техническую поддержку через другую программу, мы настоятельно рекомендуем Вам получить обратную связь по вашим вопросам в этом пошаговом руководстве.
** Проверка проекта: цели системы машинного обучения**
Как объяснялось выше, я теперь прошу Вас объединиться в пару с коллегой или в команду и просмотреть ответы друг друга на шаги, описанные выше (1–3), задавая себе следующие вопросы:
Четкое описание проблемы: Вы понимаете цель модели?
Неудача и успех: Будучи сторонним лицом, сможете ли вы оценить успех или неудачу системы машинного обучения, основанной на определенных метриках и целях? Приведите пример того, где вы будете судить о том, что в системе имеются сбои (неудачна).
Шаг 4: Определите ваш идеальный результат
Напишите результат, который вы хотите, чтобы производила ваша модель машинного обучения. Еще раз, запишите: «Результат нашей модели машинного обучения будет: ____» и «Он определен как: ____». Скажем, результат вашей модели машинного обучения будет одним из 3 классов видео {очень популярный, в некоторой степени популярный, не популярный}. Он будет определяться как верхний {3, 7, 90} — процентиль времени просмотра через 28 дней после загрузки.
Помните, что результат-выходные данные должны быть количественно измеримыми со значением, которое может произвести машина. Например, «пользователь, который наслаждался чтением статьи» даст гораздо хуже результаты, чем «пользователь, который поделится статьей». Спросите себя, можете ли вы получить примеры выходных данных, которые можно использовать в режиме обучения. Как и из какого источника вы получите это? Ваши выходные данные могут нуждаться в разработке, как в примере выше, который преобразует время просмотра видео в процентиль.
На этом этапе, если Вам трудно получить примеры выходных данных, которые можно использовать для обучения, Вам, возможно, придется пересмотреть свои ответы на прошлые шаги, чтобы переформулировать вашу проблему и цели в те, которые позволят Вам обучить модель на ваших данных.
Шаг 5: Используйте результаты
Подумайте, когда ваши результаты должны быть получены из модели машинного обучения, и как они используется в вашем продукте. Запишите: «Выходные данные модели машинного обучения будут: ____», и «Результат будет использоваться для: ____».
Например, прогноз популярности видео будет сделан, как только будет загружено новое видео. Результат будет использован для определения алгоритма перекодирования видео.
Подумайте, как вы будете использовать прогнозируемый результат в вашем продукте. Будет ли он немедленно представлен пользователю в пользовательском интерфейсе? Будет ли это использовано последующей бизнес-логикой? Какие требования к времени задержке у Вас есть?
Эти требования (которые также являются требованиями к модели машинного обучения) могут влиять на то, какая информация может быть использована для прогнозирования. Например, задержка в использовании данных из удаленных служб может сделать их недостижимой для использования. Если источники данных отстают в предоставлении новой информации доступной, то обработанные журналы могут создаваться только один раз в день, и / или определенная информация не известна до тех пор, пока это не случится (например, события преобразования).
Шаг 6: Определите вашу эвристику
Прежде чем двигаться дальше, давайте сделаем паузу и подумаем, как бы вы решили проблему, если бы не использовали машинное обучение (например, какую эвристику вы могли бы использовать). Запишите: «Если бы мы не использовали машинное обучение, мы бы: ____». Например, если вы не используете машинное обучение, вы бы предположили, что новые видео, загруженные создателями, которые загружали популярные видео в прошлом, снова станут популярными. Вот пример сценария, в котором Вам нужно представить продукт завтра, и вы можете только жестко кодировать бизнес-логику. Чтобы вы сделали? Запиши это.
** Проверка проекта: выходные данные **
Объединитесь в пару с коллегой или в команду и просмотрите ответы друг друга на приведенные выше шаги (4–6) в соответствии со следующими критериями:
Результаты модели: будет ли модель машинного обучения давать применимый и полезный результат?
Эвристика: Существует ли разумный набор эвристик, которые можно использовать для первоначального тестирования концепции без использования машинного обучения? Как их можно улучшить? Какие дополнительные эвристики вы можете предложить?
Шаг 7: Сформулируйте вашу проблему как проблему машинного обучения
Прежде чем мы перейдем к выяснению того, какой тип машинного обучения вы должны использовать развертывать для решения вашей проблемы, вот краткий обзор четырех основных способов, которыми машинное обучение может быть эффективно развернуто сегодня: 1) Классификация (какой из n меток?), 2) регрессия (предсказание числовых значений), 3) кластеризация (наиболее похожие другие примеры), 4) генерация (формирование) (комплексный результат). Обратитесь к материалу MLCC, если Вам не понятна классификация различных моделей.
Теперь запишите, что вы считаете лучшим техническим решением вашей проблемы. Например, ваша проблема может быть развернута как трехклассная классификация по одной метке, которая предсказывает, будет ли видео в одном из трех классов {очень популярное, в некоторой степени популярное, не популярное} через 28 дней после загрузки.
Шаг 8: представьте вашу проблему как «простую» проблему
Когда впервые только начинаешь, более простые формулировки проблемы легче обдумывать и выполнять. Я рекомендую взять данную Вам проблему и указать ее как бинарную классификацию или одномерную регрессионную проблему (задачу регрессии) (или обе). К примеру: «Мы предскажем, будут ли загруженные видео скорее наиболее популярными (бинарная классификация)» или «Мы спрогнозируем, насколько популярным будет загруженное видео с точки зрения количества просмотров, которое оно получит в течение 28 дней (регрессия)».
** Проверка проекта: моделирование **
Объединитесь в команду и просмотрите ответы друг друга на вышеуказанные шаги (7–8) в соответствии со следующими критериями:
Общий подход: кажется ли, что предложенные модели решат указанную проблему? Почему или почему нет?
Первый проект: В достаточной мере ли упрощенная модель упрощена и сокращена? Опишите, как можно еще больше упростить проект.
Шаг 9: Создайте свои данные для модели
Запишите данные, которые вы хотите, чтобы модель машинного обучения использовала для прогнозирования, в следующую таблицу:
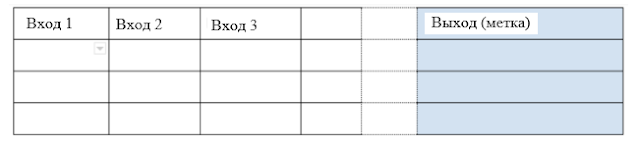
Одна строка представляет собой один фрагмент данных, для которого сделан один прогноз. Вы должны включать только ту информацию, которая доступна на момент составления прогноза.
К примеру:
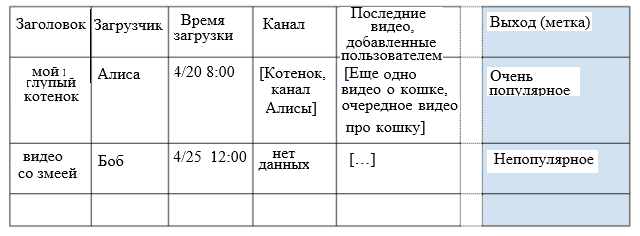
Шаг 10: выясните, откуда берутся ваши данные
Давайте запишем, откуда поступают входные данные, и оценим, сколько потребуется работы для разработки конвейера данных, чтобы построить каждый столбец для строки. Ознакомьтесь с ресурсами, которые помогут Вам продумать, какие данные внести в вашу модель, и как настроить группу аннотирования данных после их сбора.Подумайте о том, когда тестовые выходные данные станут доступны для учебных целей. Если тестовые выходные данные получить сложно, вы можете вернуться к шагу 5 (ваш результат) и проверить, можете ли Вы использовать другой вывод для вашей модели.Убедитесь, что все ваши входные данные доступны во время обслуживания (когда сделан прогноз), именно в том формате, в котором вы записываете. Если Вам трудно получить все ваши входные данные во время обслуживания в одном и том же формате, вы можете вернуться к шагу 9 (Проектирование ваших данных для модели), чтобы пересмотреть входные данные, или к шагу 5 (обслуживание выходных данных), чтобы пересмотреть, когда обслуживание может быть выполнено.
Пример

Шаг 11: Сосредоточьтесь на легко получаемых данных
Среди входных данных, которые вы перечислили на шаге 9, выберите из них 1-3, которые легко получить и которые, как вы считаете, дадут разумный исходный результат.
На шаге 6 вы перечислили набор эвристик, которые можете использовать. Какие входные данные будут полезны для реализации этих эвристик? Рассмотрите затраты на разработку конвейера данных для подготовки входных данных и ожидаемую выгоду от наличия каждого входа в модели. Сосредоточьтесь на входных данных, которые могут быть получены из одной системы с простым конвейером. Начинать с минимально возможной инфраструктуры рекомендуется при первом выполнении.
** Проверка проекта: данные **
Объединитесь в команду и просмотрите ответы друг друга на приведенные выше шаги (9–11) в соответствии со следующими критериями.Простые входные данные: Является ли набор «простых функциональных возможностей входных данных» достаточно упрощенным и легким в получении? Как эти входные данные могут быть еще более упрощены?Метки: Сможете ли вы получить выходные примеры (метки) для учебных целей?Предвзятость: любой набор данных будет содержать в себе предвзятость каким-либо образом. Эти предубеждения могут отрицательно повлиять на обучение и сделанные прогнозы. Например, векторные представления слов, обученные из определенного источника данных, могут иметь предвзятость, непригодную для их использования в другом контексте. Или наборы данных для обучения могут быть нерепрезентативными для конечных пользователей моделей. Перечислите некоторые потенциальные источники предвзятости в наборах данных, которые будут использоваться (и обратите внимание на некоторые удивительные ресурсы, которые должны быть воплощены беспристрастной командой по машинному обучения Google ближе к маю 2019 года).Риски и сложность реализации: Перечислите аспекты проекта, которые могут быть трудными для реализации, рискованными, чрезмерно сложными или ненужными.Способность к обучению: сможет ли модель машинного обучения учиться? Перечислите сценарии, в которых система может испытывать трудности при обучении. Например, отсутствие достаточных положительных примеров, что данные обучения могут быть слишком маленькими, метки слишком громкими, что системе может быть сложно обобщать данные для новых случаев и т. д.
Шаг 12: Определите свою собственную комплексную систему машинного обучения
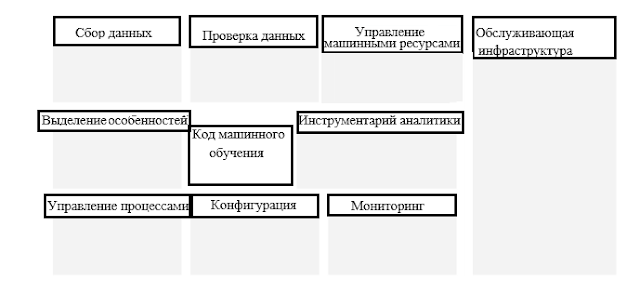
Шаг 13: Следующие шаги
После заполнения этой технологической карты и получения обратной связи по проекту, ваша первая реализация должна основываться на упрощенной модели (двоичной классификации или регрессии) с использованием нескольких (1–3) легко получаемых входных данных. Как только эта базовая настройка сработает, вы можете повторить проект, чтобы приблизить его к конечному виду. Когда вы будете готовы «сделать это сами», ознакомьтесь с этим ресурсом. Удачи! Дайте нам знать, что получится.Малика Кантор (Malika Cantor) на глобальном уровне занимает ведущую роль в Google Developers Launchpad и является редактором блога The Launchpad. Ранее она была партнером-основателем в Comet Labs, экспериментальной исследовательской лаборатории и венчурной фирме, которая занималась поддержкой стартапов в области машинного обучения на ранних этапах. Следите за вопросами / комментариями в разделе комментариев и / или твитом!Огромная благодарность Ола Бен Хару, Пшемеку Виктору Парделу, Александру Захарчуку, Павлу Новаку и т. д. за организацию мероприятия «Машинное обучение на Кикстартере» в Варшаве и создание рабочего листа по развертыванию проблемы машинного обучения (широко освещаемого в посте). Спасибо команде Google EngEdu за официальное решение проблемы создания контента в конце прошлого года. СПАСИБО Томасу Дж. Уайту IV и Бретту Камите за редактирование и корректирование, Джереми Нойнеру за визуальные эффекты и шутки, Джошуа Йеллин, Нишу Лахоти и Ричарду Хиндману, Майу Гроссману и Дженнифер Харви за маркетинг, Питеру Норвигe и Кэсси Козыркову за то, что они были моими партнерами по преступлению.
Источник : edwvb.blogspot.com



