
Классификация функционала HR: первый заход

Это на самом деле всего лишь первый заход, поскольку пост не результат специальной работы над темой: я готовлюсь к семинару «HR-Аналитика в R», Москва, 20-21 июня 2017, думаю, давать ли там кластеризацию. Но если давать, то давать на примере кластеризации текстов.
И поигрался с данными нашего опроса: есть открытый вопрос о функционале. Мы можем посмотреть, как наш функционал можно разбить на кластеры — т.е. на классы по функционалу.
Получилось вот что. Повторюсь: глубоко я не залезал. Работал в R, планирую сделать более глубокий анализ позже, но в Python, поэтому пока просто не хочу выполнять дополнительную работу по улучшению классов. Какую — читайте ниже. Если Вы специалист, с удовольствием послушаю ваши рекомендации по улучшению классификации.
K-means
В кластеризации есть два основных алгоритма, я покажу результаты по обоим. Начну метода ближайших соседей — k-means.
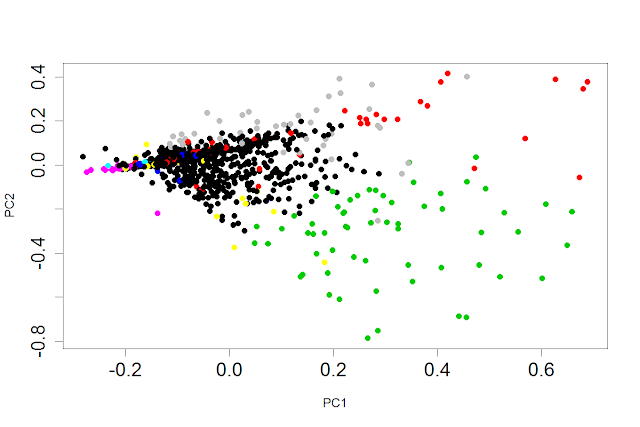
На данной картинке показаны кластеры по двум факторам. Начнем с того, что два этих фактора описывают 26 % разброса функционала, что не дает нам очень точного представления о кластерах на основе этой картинки. Тем не менее, заметно очень плотное сосредоточение точек черного пятна. Ниже даю описание кластеров (в конце цифра — сколько респондентов было отнесено к тому или иному кластеру):
- Cluster 1 : generalist компенсац льгот — 50
- Cluster 2 : адаптац персона подбор — 69
- Cluster 3 : обучен оценк персона подбор развит — 103
- Cluster 4 : рекрутмент — 26
- Cluster 5 : hrd — 16
- Cluster 6 : директор персонал управлен — 45
- Cluster 7 : рекрутинг — 43
- Cluster 8 : администрирован делопроизводств кадров подбор — 62
- Cluster 9 : hrgeneralist отдел персона подбор руководител управлен — 820
- Cluster 10 : единствен лиц специалист — 31
Я пока не обсуждаю результаты, просто показываю. Не пугайтесь обрезанных слов — это было сделано машиной специально. Профессионалы поймут, что это стемминг по методу Портера — машина отсекает окончания, чтобы привести слова к единому формату, а мы после этого можем их сравнивать.
Иерархический кластерный анализ
- Cluster 1 : обучен оценк персона подбор развит — 65
- Cluster 2 : кадров обучен организац оценк персона персонал подбор развит разработк управлен — 980
- Cluster 3 : адаптац администрирован делопроизводств кадров мотивац оценк персона подбор — 44
- Cluster 4 : generalist — 30
- Cluster 5 : адаптац рекрутинг — 22
- Cluster 6 : директор персонал — 22
- Cluster 7 : адаптац персона подбор — 49
- Cluster 8 : hrd — 15
- Cluster 9 : компенсац льгот — 20
- Cluster 10 : рекрутмент — 18
Интересно, что кластеры сильно похожи, хотя машина не обязана, чтобы номера кластеров совпадали) Очевидно, что второй кластер иерархической кластеризации соответствует девятому классу метода ближайших соседей k- means. Но при этом, обратите, что k-means лучше разносит респондентов по классам (в k-means в самом большом классе 820 наблюдений, а в иерархической кластеризации — 980, то есть в первом случае машина дает большее разнообразие классов).
Обсуждение результатов
Очевидно, что данный результат, мягко говоря, не очень хорош.
Проблема, как я понимаю, в том, что у нас из описания функционала в описание функционала повторяются одни и те же слова, которые машина потом объединяет в один большой класс, и который потом очень сложно расчленить на отдельные классы. Что можно сделать?
- Объединение выражений. Например, у нас есть классы «hrd» и «директор персонал» и «рекрутинг» и «рекрутмент». Совершенно спокойно мы можем с помощью методов регулярных выражений привести эти слова / выражения к единой форме. Заодно, скажу по практике, таким же образом «c&b» мы перекодируем в «компенсации и льготы», а «t&d» в «обучение и развитие».
- Некоторые наиболее часто встречающиеся слова типа «персоналом» и т.п. можно отнести к мусору, поскольку они не несут содержания функции (например, многие пишут «управление персоналом», что не дает нам никакой пользы для классификации), и просто удалить из анализа.
Источник : edwvb.blogspot.com



