
Прогноз уровня добровольной текучести в компании

Если в той статье я говорю о том, что не имеет смысла прогнозировать увольнение конкретного работника, в этой я хочу показать пример того, чем, на мой взгляд, имеет смысл заниматься.
Также этот пост можно воспринимать как коммерческое предложение.
На диаграмме ниже — количество уволившихся по собственному желанию в разрезе по месяцам.
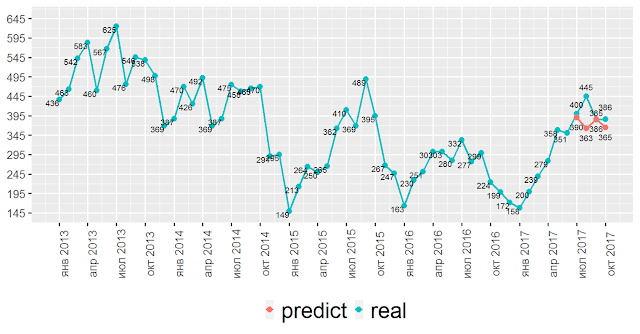
Мы можем прогнозировать это число. И показать на вашем дашборде.
Это может быть полезно для планирования нагрузки рекрутеров. А также для понимания факторов, которые влияют на нашу текучесть. Если мы фиксируем текущую текучесть, то можем показать прогнозную текучесть.
Не удивляйтесь тому, что на диаграмме 2013-2017 годы — других данных у меня нет.
Как мы прогнозируем
Если посмотреть разброс текучести по месяцам, то он за эти годы дает такую картину.
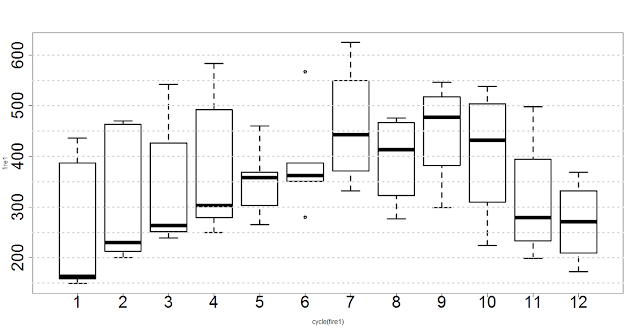
Заметно различие числа увольняющихся в разрезе по месяцам. Чемпионы оттока — сентябрь и июль. Но нам это приятно, потому что на основе этой информации мы можем прогнозировать будущую текучесть.
Найм
Поскольку мы прогнозируем не просто % текучести, а число уволившихся, то очевидно, что размер найма также должен влиять на будущий отток. Т.е.
Для любителей покопаться в основаниях сообщаю инфо: самое сильное влияние на будущий отток оказывает найм с лагом 2 месяца. Т.е. на отток в сентябре влияет размер найма в июле. Понятно, что это не общий закон, это данные конкретно взятой компании, у вас могут быть свои законы, тем не менее, было бы интересно понять, какой механизм в основе этого влияния. Но явно не потому, что через два месяца новички побежали.
Другие факторы
у меня в наличии были только эти факторы, но ничто нам не мешает включить любые другие переменные, включая внешнеэкономические типа % безработицы в России и так далее.
Качество модели
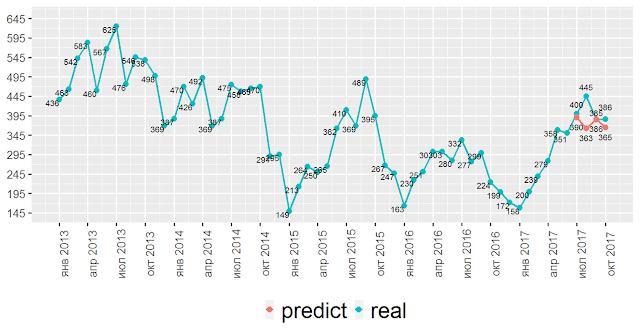
Если вы будете делать у себя прогноз уровня добровольной текучести, то вы должны отдавать отчет в том, что прогноз не может быть идеальным, и вы должны уметь оценивать качество прогноза — не аналитики, а вы сами. Чтобы аналитики вас не смогли обмануть.
Проверка такая: вы создаете модель, отрезав несколько последних месяцев, в моем случае я отрезал четыре последних месяца. Потом делал прогноз на них. На диаграмме красная линия — это прогноз. Обратите внимание, что хуже всего прогноз у нас по августу 2017 года. Это нихт гут, но в оправдание модели предлагаю посмотреть прошлые периоды — после роста текучести в июле следует падение текучести в августе, поэтому можно сказать, что в августе оказал влияние какой-то неучтенный фактор. Я выше писал о том, что такие модели позволяют понимать внутренние процессы в компании. Это как раз такой случай, когда что-то идет в другой логике, а для нас это повод для понимания и рефлексии, что происходит.
На диаграмме заметно, что на фоне разброса текучести за весь период красная линия вроде бы не так сильно отстает от реальных данных, но нам нужно не вроде бы, а четкий ответ: можем ли мы сказать, что наш прогноз выше плинтуса.
Методика такова.
- Мы должны посчитать сумму или среднее значение абсолютных значений отклонений прогнозных значений от реальных (400 и 390, 445 и 363, 385 и 386, 386 и 365). Пусть это будет некое число X;
- Далее мы считаем сумму или среднее разницы абсолютных значений между значением текучести текущего месяца с текучестью предыдущего (400 и 351, 445 и 400 и так далее). Это и есть наш «плинтус». Т.е. самый простой элементарный прогноз это когда мы предполагаем, что в следующем месяце у нас уйдет столько же, сколько в этом. Пусть это будет число Y;
- Это такой наивный подход, но он позволяет оценить качество модели. Если у нас первое число — X — будет больше, чем Y — т.е. если разброс между реальными и прогнозными значениями будет больше, чем разница между текущим и предыдущим значением, то какой прок в этой модели?
- В нашем случае число X или среднее значение отклонения прогноза от факта составляет 28, 25 (т.е. мы в среднем ошибаемся на такое число увольняющихся), а число Y — средняя разница между числом увольнением текущего и прошлого месяца — 38, 75 — мы делаем вывод, что наша модель выше плинтуса и применима на практике.
Предостережение
Если вы закажете у меня создание такой модели и визуализации ее на дашборде, то сразу давайте договоримся:
- горизонт прогноза не должен превышать 3 месяца, дальше вероятная ошибка / разброс значений будет уже неприличным;
- данных должно быть не менее чем за 5 лет;
- каждый месяц надо будет пересчитывать прогноз — этому можно научить.
Источник : edwvb.blogspot.com



